Clustering Wine Review Text and Using KNN to Predict Future Reviews
Posted on August 15, 2021 in Wine
Premise and Data Set
Using the wine data that has been collected previously, we will be using the Google Colab environment to look into clustering wine reviews. We will have 20 holdout reviews, so that after forming the clusters, we can use a KNN algorithm to classify the 20 holdouts to either cluster
We will first mount the drive and import the JSON data
from google.colab import drive
drive.mount('/content/drive')
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn.feature_extraction import text
from sklearn.metrics.pairwise import euclidean_distances
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import random as rand
import regex as re
import matplotlib.pyplot as plt
# Import data
# 'wineNameProducer', 'wineVarietalRegion', 'wineYear', 'score', 'price', 'country', 'region', 'reviewDate', 'notes'
data_file = '/content/drive/My Drive/TAMU/STAT684/2018-09-09data.json'
raw_df = pd.read_json(data_file, dtype={'score': int})
raw_df.head()
| reviewId | wineNameProducer | wineVarietalRegion | wineYear | score | price | country | region | reviewDate | notes | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 23945 | CORBETT CANYON(CALIFORNIA) | Merlot California Coastal Classic | 1991 | 79 | 6 | California | Other California | Nov 30, 1992 | Light, smooth and fresh, this medium-bodied, n... |
| 1 | 23946 | SEPPELT | Cabernet Sauvignon-Shiraz South Eastern Austra... | 1989 | 79 | 8 | Australia | Australia | Nov 30, 1992 | Rustic and earthy, with prune and cherry flavo... |
| 2 | 23947 | PROSPER MAUFOUX | Sancerre | 1990 | 79 | 17 | France | Loire | Nov 30, 1992 | An oddball of a Sancerre. The heavy woody arom... |
| 3 | 23948 | FLORA SPRINGS | Merlot Napa Valley Floréal | 1990 | 79 | 14 | California | Napa | Nov 30, 1992 | Hard, green and stemmy, with harsh oak flavors... |
| 4 | 23949 | FIRESTONE | Merlot Santa Ynez Valley | 1990 | 79 | 13 | California | South Coast | Nov 30, 1992 | This solid, well-balanced red has crisp cherry... |
20 holdout reviews were randomly sampled to use for KNN classification later
Then text processing was performed * Remove reviews with length less than 50 characters. The 50 characters was chosen arbitrarily, but the intent was to remove reviews with reduced text such as "30,000 cases made. Drink now" * Remove additional text processing is executed to convert all the text to lower, remove letters and " s " that occurs from removing the ' symbol
A tf-idf vectorizer was fitted on the training dataset with a stop word list that included english words as well as common words to the wine review dataset such as drink, cases, flavors, etc. The TF-IDF processor converts each word into a count weighted by how often they appear in the reviews. We set a cutoff of thateach word must appear at least 10 times to be considered in the dataset.
A K-Means clustering algorithm was then run upon the transformed training dataset. Running with the algorithm with 2 clusters found a white and red cluster of reviews as seen below by the top words in each cluster as well as the reviews that are closest to the center of the cluster
# Remove reviews that are shorter than 50 characters
raw_df['review_len'] = raw_df['notes'].str.len()
raw_df = raw_df[raw_df['review_len'] > 50]
# Create custom stop words
NUMBERS_REGEX = re.compile('[0-9]')
def clean_text(text):
text = text.lower() # lowercase text
text = NUMBERS_REGEX.sub(' ', text) #remove numbers from text
text = text.replace(' s ', '') #remove the 's' char
return text
raw_df['cleaned_notes'] = raw_df['notes'].apply(clean_text)
rand.seed(10)
test_mask = rand.sample(range(0, len(raw_df)), 20)
train_mask = [elem for elem in range(0,len(raw_df)) if elem not in test_mask]
test_df = raw_df[raw_df.index.isin(test_mask)]
train_df = raw_df[~raw_df.index.isin(test_mask)]
custom_stop_words = text.ENGLISH_STOP_WORDS.union(["drink", "cases", "flavors", "finish", "imported", "notes", "best"])
text_vectorizer = TfidfVectorizer(stop_words = custom_stop_words, min_df= 10, token_pattern=u'(?ui)\\b\\w*[a-z]+\\w*\\b')
text_vectorizer.fit(train_df['cleaned_notes'])
x = text_vectorizer.transform(raw_df['cleaned_notes'])
# Three clusters generates the categories (white, light reds, dark reds)
# Two clusters generates whites and reds
num_clusters = 2
model = KMeans(n_clusters = num_clusters, init='k-means++', max_iter = 100, n_init = 1)
clusters_output = model.fit_predict(x[train_mask])
#https://stackoverflow.com/questions/34226400/find-the-index-of-the-k-smallest-values-of-a-numpy-array
def get_indices_of_k_smallest(arr, k):
idx = np.argpartition(arr.ravel(), k)
return tuple(np.array(np.unravel_index(idx, arr.shape))[:, range(min(k, 0), max(k, 0))])
print("Top terms per cluster:")
order_centroids = model.cluster_centers_.argsort()[:, ::-1] #Gets terms closest to the cluster center
terms = text_vectorizer.get_feature_names() #get terms
for i in range(num_clusters):
print ("Cluster %d:" % i)
for ind in order_centroids[i, :20]:
print (terms[ind])
#https://stackoverflow.com/questions/25829358/how-to-find-documents-that-are-in-the-same-cluster-with-kmeans
# Example to get all reviews in cluster
cluster_0 = np.where(clusters_output==i)
# cluster_0 now contains all indices of the reviews in this cluster, to get the actual documents you'd do:
X_cluster_0 = x[cluster_0]
d = euclidean_distances(X_cluster_0, model.cluster_centers_[i].reshape(1,-1))
a = np.argmin(d)
closest_ind_to_center = get_indices_of_k_smallest(d, 10)
print()
print("10 review's closest to center of cluster %d:" % i)
for ind in closest_ind_to_center[0]:
print("- " + raw_df.iloc[cluster_0[0][ind]]['notes'])
print()
Top terms per cluster:
Cluster 0:
cherry
tannins
red
plum
berry
fruit
medium
black
bodied
currant
firm
ripe
spice
light
aromas
blackberry
character
fresh
dark
raspberry
10 review's closest to center of cluster 0:
- A silky red, with berry, plum and cherry character. Medium-bodied, with fine tannins and a fruity finish. Best after 2006. 13,000 cases made.
- A fresh, medium-bodied red with firm plum and black currant fruit, spice and tobacco notes. Drink now. 12,000 cases made.
- Some berry and spice character in this medium-bodied red, with firm tannins and a light finish. Best after 2006. 600 cases made.
- A medium- to light-bodied red, with plum, dried cherry and cedar character, light tannins and a spicy finish. Drink now. 1,100 cases made.
- A fruity red with dark plum, berry and light chocolate character. Medium-bodied, with fine tannins and a fresh finish. Drink now. 2,750 cases made.
- Some good fruit with berry and cherry character. Medium-bodied, with light tannins and a fresh finish. Drink now. 26,000 cases made.
- Good fruit, with berry and black cherry character. Medium-bodied, with firm tannins and a light finish. Best after 2008. 45,415 cases made.
- Crushed black cherry and plum fruit is accented by hints of herb, spice, tar and rich earth in this fresh red, which is medium-bodied and balanced, with light tannins on the finish. Drink now through 2018. 250 cases imported.
- A medium-bodied red, with plum, black fruit and vanilla character. Medium-bodied, with fine tannins. Firm finish. Drink now. 3,330 cases made.
- There's some berry and cherry character in this medium-bodied red. Light and earthy, but has good fruit. Drink now. 840 cases made.
Cluster 1:
apple
pear
white
peach
lemon
citrus
acidity
fresh
light
crisp
ripe
honey
melon
green
mineral
spice
lime
floral
apricot
fruit
10 review's closest to center of cluster 1:
- A good fruity white, with apple, pear and fresh mineral character. Medium-bodied, well-balanced, with a crisp citrus finish. Drink now. 4,160 cases made.
- Fresh and fruity, with apple, white peach and mineral character. Medium-bodied, with crisp acidity and a light finish. Drink now. 2,100 cases made.
- A fresh white, with apple and melon character. Medium-bodied, with good acidity and a crisp finish. Drink now.
- Plenty of fresh pear and apple. Medium-bodied, with a mineral and green apple character, light acidity and a clean finish. Drink now.
- A white with ripe apple, pear and almond aromas. Medium-bodied, with spicy, fruit character and a fresh finish. Drink now. 665 cases made.
- Light and simple, this white is clean and soft, with hints of apple and pear and enough acidity to keep it fresh. 1,700 cases made.
- Offers aromas of white peach and green apple. Medium-bodied, with good fruit and a crisp finish. Drink now. 1,000 cases made.
- A floral, medium-bodied white, with fresh apple, white peach and spice notes. Drink now. 6,500 cases made.
- A fresh and fruity white, with apple, honey and peach. Medium- to full-bodied, with bright acidity and a tart finish. Drink now. 500 cases made.
- A balanced and fruity white with apple, honey and light vanilla character. Medium-bodied, with ripe fruit and a crisp, fresh finish. Delicious. Drink now. 1,350 cases made.
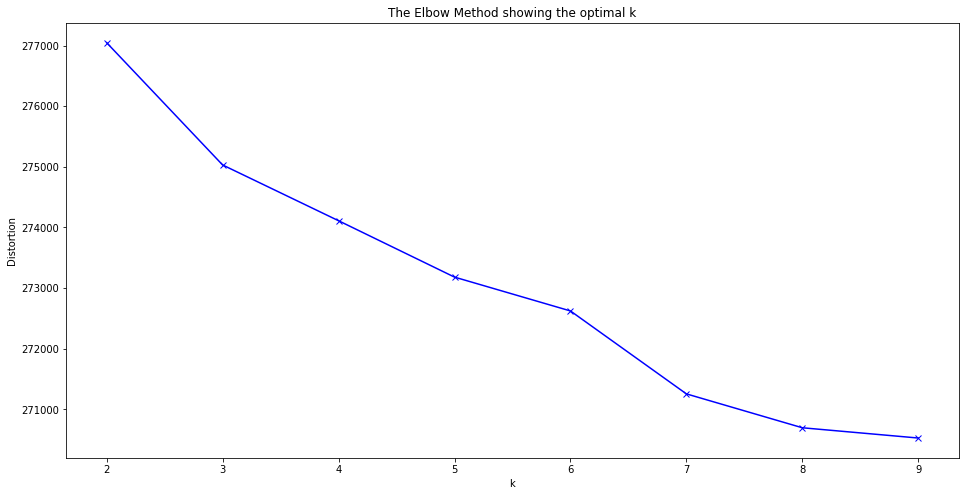
We then took a look at the review's distortion to see whether an optimal number of clusters could be identified. From the distortion plot, we ideally would like to see a clear "elbow" indicating that a particular number of clusters is preferred.
Unfotunately, we do not see an optimal number of clusters.
from sklearn import metrics
distortions = []
ch_index = []
K = range(2,10)
for k in K:
print("Fitting for " + str(k) + " clusters")
kmeanModel = KMeans(n_clusters = k, init='k-means++', max_iter = 100, n_init = 1)
kmeanModel.fit(x[train_mask])
distortions.append(kmeanModel.inertia_)
plt.figure(figsize=(16,8))
plt.plot(K, distortions, 'bx-')
plt.xlabel('k')
plt.ylabel('Distortion')
plt.title('The Elbow Method showing the optimal k')
plt.show()
Fitting for 2 clusters
Fitting for 3 clusters
Fitting for 4 clusters
Fitting for 5 clusters
Fitting for 6 clusters
Fitting for 7 clusters
Fitting for 8 clusters
Fitting for 9 clusters
Finally, we will use KNN to predict our 20 test observations into the two clusters. Cluster 0 is red wines and Cluster 1 are white wines. We see that the majority of the predictions are accurate, showing that our KNN classifier is working as expected
# Perform knn now using our clusters to predict the other 20 test observations
neigh = KNeighborsClassifier(n_neighbors=7)
neigh.fit(x[train_mask], clusters_output)
observation_num = 1
for review_ind in test_mask:
print("Test Observation " + str(observation_num))
print("Wine Varietal / Region: " + raw_df.iloc[review_ind]['wineVarietalRegion'])
print("Prediction: " + str(neigh.predict(x[review_ind])))
print()
observation_num += 1
Test Observation 1
Wine Varietal / Region: Chardonnay Carneros
Prediction: [1]
Test Observation 2
Wine Varietal / Region: Bâtard-Montrachet
Prediction: [1]
Test Observation 3
Wine Varietal / Region: St.-Nicolas-de-Bourgueil La Mine
Prediction: [0]
Test Observation 4
Wine Varietal / Region: Merlot Vin de Pays d'Oc
Prediction: [0]
Test Observation 5
Wine Varietal / Region: Cabernet Sauvignon Napa Valley
Prediction: [0]
Test Observation 6
Wine Varietal / Region: Monastrell Jumilla Dulce
Prediction: [0]
Test Observation 7
Wine Varietal / Region: Shiraz Padthaway Reserve
Prediction: [0]
Test Observation 8
Wine Varietal / Region: Barolo La Serra
Prediction: [0]
Test Observation 9
Wine Varietal / Region: Merlot Monterey County
Prediction: [1]
Test Observation 10
Wine Varietal / Region: A Red Blend Alexander Valley
Prediction: [0]
Test Observation 11
Wine Varietal / Region: Aglianico del Vulture Il Viola
Prediction: [0]
Test Observation 12
Wine Varietal / Region: Brut Trento Talento Riserva
Prediction: [1]
Test Observation 13
Wine Varietal / Region: Syrah Santa Lucia Highlands Susan's Hill
Prediction: [0]
Test Observation 14
Wine Varietal / Region: Salento Rosato Five Roses
Prediction: [1]
Test Observation 15
Wine Varietal / Region: Toscana Cletus
Prediction: [0]
Test Observation 16
Wine Varietal / Region: Charbono Napa Valley
Prediction: [0]
Test Observation 17
Wine Varietal / Region: Merlot Chalk Hill Adele's Vineyard
Prediction: [0]
Test Observation 18
Wine Varietal / Region: Amontillado Jerez Los Arcos Solera Reserva
Prediction: [0]
Test Observation 19
Wine Varietal / Region: Barbera d'Alba Vigna Gattere
Prediction: [0]
Test Observation 20
Wine Varietal / Region: Meursault
Prediction: [1]